
目录
什么是编码和解码编解码基本原理python的默认编码什么是10进制/2进制/8进制/16进制python的字符串编解码python字符串和unicode类型编码转换什么是编码和解码
大家都知道计算机是二进制的世界,计算机系统只能识别数字0和1组成的一串串的数字。1位数字代表1个比特(bit),每8个比特代表1个字节(byte),那么1个字节如果都为数字1,如11111111,代表的最大数字是255。

如果是2 个字节最大可以表示为 65535,4 个字节最大表示为4294967295。
每一种不同的数字0和1的组合,就可以代表一个字符。基于上述原理出现了各种编码格式:
ASCII 编码
ASCII(American Standard Code for Information Interchange,美国信息交换标准代码)字符集是一个基于拉丁字母的字符编码系统,它主要用于显示现代英语和其他西欧语言。ASCII字符集共定义了128个字符,每个字符都有一个对应的数字,这个数字被称为码点(code point)。可最大扩展为 256 个字符,仅支持英文字母,数字和少部分符号,不支持中文。
以下是ASCII字符集中一些常见的字符及其对应的数字(码点):
空字符(Null):0控制字符(如LF、CR、FF、DEL等):1-31(共31个)数字0-9:48-57大写英文字母A-Z:65-90小写英文字母a-z:97-122标点符号、运算符号等:其他码点(如33表示"!",34表示"""等)删除字符(DEL):127GBK 编码
中国文字博大精深,汉字特别多,其他编码格式并不能满足要求,所以才有了适合中文编解码的 GB2312。编码(后来升级到了 GBK 编码),可以容纳将近7000个汉字。
Unicode
世界上除了英文/中文等还有各个国家的文字语言,每个国家的编码不统一会带来很多编解码的困难,后来Unicode 字符集就出现了,它将所有的语言都容纳在一起,后续为了在存储和传输数据时节省空间,出现了目前常用的UTF8编码。
编解码基本原理
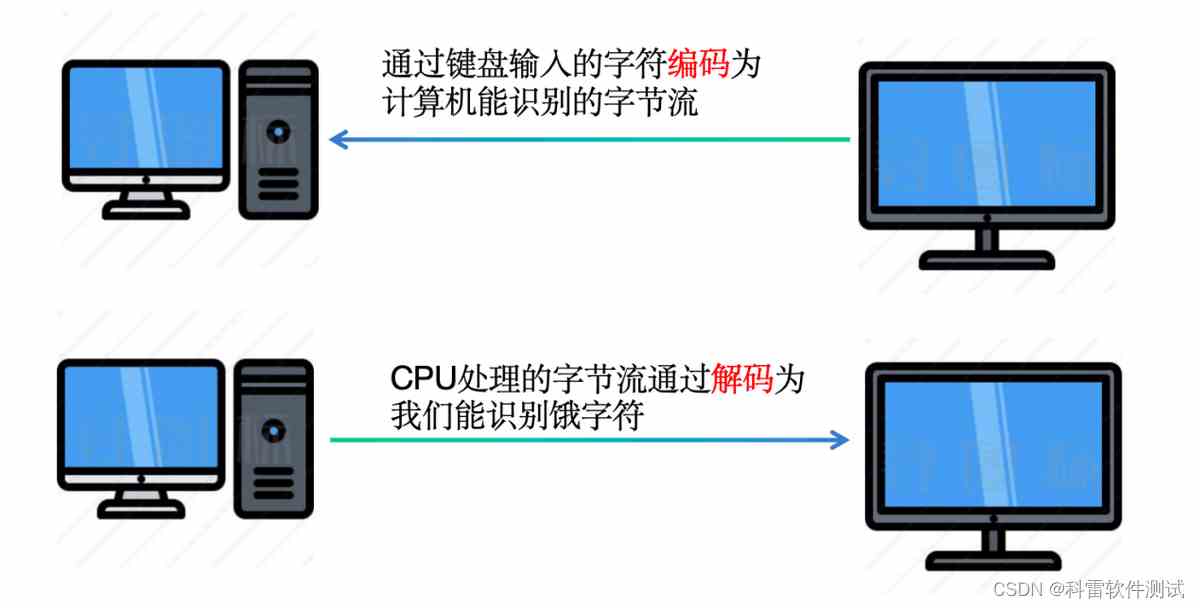
平常工作中,我们通过键盘输入英文字符或者中文字符或者一些逗号等符号,程序通过编码将字符转为计算机识别的2进制字节流,当计算机处理完成后再通过解码转为我们能识别的字符。
python的默认编码
安装完python3版本的程序后,我们通过sys库,检查下默认的编码。
import sysprint(sys.getdefaultencoding())
结果:
utf-8
因为utf-8本来就支持中文,所以我们可直接在python3版本上定义中文变量并直接使用,而不会出现乱码问题。
什么是10进制/2进制/8进制/16进制
10进制通常我们说的数字,比如数字10 100 200等,没有前缀表示2进制由数字0和1组成,以0b或者0B前缀开头,比如0b1010,换算为十进制表示数字108进制由数字0到7组成,每3位2进制数字组成一个8进制数,比如3位111表式数字7,所以最大数字为7,而000就表示为0。以0O或者0o前缀开头,比如0o12,换算为十进制表示数字1016进制由数字0到9,字母a,b,c,d,e,f共16位组成,字母a到f代表的是数字10到15;相当于每4位2进制数字组成一个16进制数,比如4位1111表式数字15,用f表示,而0000就表示为0。
以0x或者0X开头,比如0xa,换算为十进制表示数字10
python中可通过bin(),oct(),hex()函数依次将十进制数转换为2进制,8进制,16进制。
#定义数字10dig1 = 10 #转为2进制bin_dig1 = bin(dig1)print(f'十进制 数字10 转为2进制为:{bin_dig1}') #转为8进制oct_dig1 = oct(dig1)print(f'十进制 数字10 转为8进制为:{oct_dig1}') #转为16进制hex_dig1 = hex(dig1)print(f'十进制 数字10 转为16进制为:{hex_dig1}')结果:
十进制 数字10 转为2进制为:0b1010
十进制 数字10 转为8进制为:0o12
十进制 数字10 转为16进制为:0xa
同理2进制,8进制和16进制可通过int()函数转为10进制。
print(f'2进制 数字10 转为10进制为:{int(bin_dig1,base=2)}')print(f'8进制 数字10 转为10进制为:{int(oct_dig1,base=8)}')print(f'16进制 数字10 转为10进制为:{int(hex_dig1,base=16)}')结果:
2进制 数字10 转为10进制为:10
8进制 数字10 转为10进制为:10
16进制 数字10 转为10进制为:10
python的字符串编解码
使用str.encode()编码 ,str.decode()解码
userinfo = '章三'
以 encoding 指定的编码格式编码 string, 默认会使用‘utf-8’编码,所以encoding='utf-8'这个参数可以不带; 如果采用其他编码格式,需要带上encoding参数。
userinfo_byte = userinfo.encode(encoding='utf-8')print(userinfo_byte)#结果显示被编码为 前缀带字母b的字节码b'\xe7\xab\xa0\xe4\xb8\x89'
编码后字符串类型为bytes,输出的是16进制的字节码,而且1个中文字占了3个字节
print(type(userinfo_byte))<class 'bytes'>
通过decode函数解码字节码为字符串。
print(userinfo_byte.decode())章三
再举个例子: 比如我们在http请求拿到的响应中,body体为'sdsdsdsdsdAAAAA10000000-s\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0\xe4\xb8\xad\xe5\x9b\xbd',像这种既有字母符号 又有一些十六进制的字符,一般都是编码后的字节码(因为英文字母/符号本身就支持ASCII码,转码后也会保留原样子)。 此时我们在这些字符串加上字母b的前缀,然后用decode函数节码就得到原字符串
str_b = b'sdsdsdsdsdAAAAA10000000-s\xe6\x88\x91\xe7\x88\xb1\xe4\xbd\xa0\xe4\xb8\xad\xe5\x9b\xbd'print(str_b.decode())
解码后打印结果:
sdsdsdsdsdAAAAA10000000-s我爱你中国
解码的乱码问题
如果编码和解码使用的编码不一样,解码后会出现乱码。 比如下面的示例将中文通过utf-8编码,然后通过gbk解码
使用bytes()函数定义编码格式为utf-8的字节码,解码使用gbk编码
zhongwen = bytes('章三',encoding='utf-8')print(zhongwen.decode(encoding='gbk'))打印结果时出现乱码:
绔犱笁
所以我们在平时使用时一般都是统一编码格式,目前使用的都是默认编码utf-8。
16进制字符串解码为普通字符串
")
")
")
")